
Per fare chiarezza su alcune espressioni usate nella cybersecurity abbiamo avviato questa serie di approfondimenti nel nostro blog. Ci siamo già occupati di Adaptive Redaction e Ispezione dettagliata dei contenuti e ora parliamo di Information Governance Servers.
Considerando che le informazioni e i dati sono tra le risorse più preziose per molte aziende, conservarle al sicuro è una priorità. Un IGS, Information Governance Server, è una maniera decisamente efficace per farlo. In questo articolo spiegheremo che cos’è e come può proteggere dati sensibili.
Prevenire le violazioni di dati
La DLP, Data Loss Prevention, è una richiesta fondamentale per l’integrità delle attività aziendali e per la sicurezza dei dati. Le violazioni causano gravi danni alle aziende, tanto quanto la perdita di dati critici e a ciò si uniscono alti costi di recupero e pesanti sanzioni da parte degli enti regolatori. Clearswift Information Governance Server è una soluzione centralizzata che lavora in background per minimizzare i rischi di una esflitrazione dei dati, sia accidentale che intenzionale.
Sovraccarico di informazioni
Nessuno mette in discussione la notevole quantità di informazioni generata e gestita nei vari settori aziendali ma non tutte hanno la stessa importanza in termini di sicurezza. In qualsiasi organizzazione esistono informazioni che sono particolarmente importanti, che si tratti di assicurare la loro conformità a regolamenti come il GDPR o che i dati contengano materiale protetto da IP, Intellectual Propriety, oppure ancora che le informazioni siano riservate.
Registro dei dati
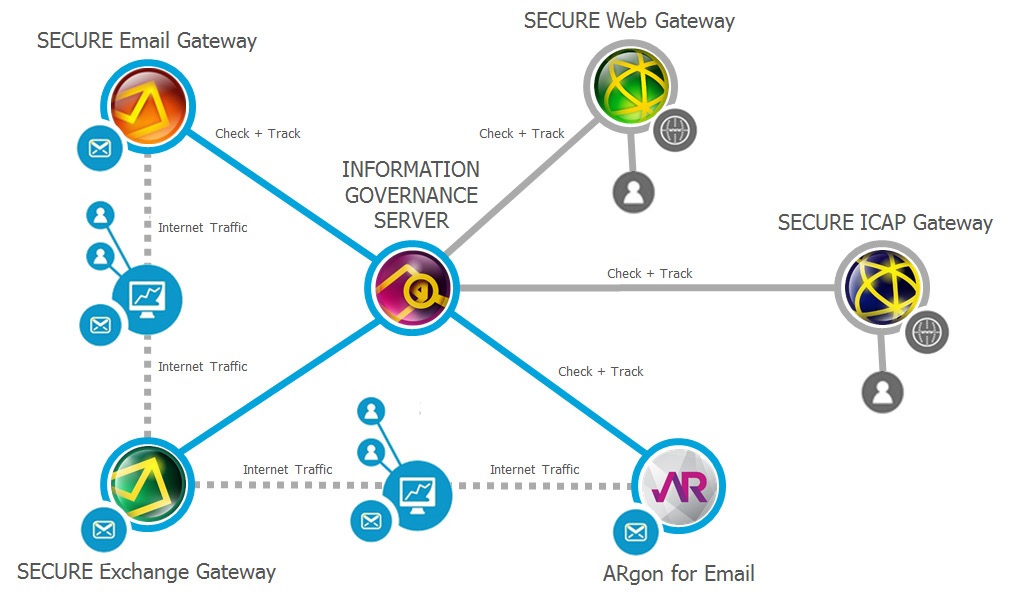
L’Information Governance Server permette alle organizzazioni di identificare, gestire e proteggere dati critici non strutturati quando circolano all’interno e all’esterno delle organizzazioni stesse. Gli utenti registrano i documenti che contengono informazioni sensibili e assegnano il rispettivo livello di classificazione e contesto.
Quando si registra il documento, l’IGS crea un file hash completo e contemporaneamente una serie di hash di tutto il file. Grazie alla scansione OCR si arriva anche a includere l’eventuale contenuto di testo inserito nelle immagini, per esempio il numero di passaporto in un’immagine scansionata. Questo processo è noto come fingerprinting, che può essere totale o parziale. Il fingerprinting permette a IGS di tracciare porzioni di informazione anche se sono state tagliate e incollate in nuovi documenti o se i file sono stati rinominati o convertiti da un formato a un altro (per esempio da .doc a .pdf)
Il file originale non viene conservato nell’IGS: quest’ultimo semplicemente effettua le ricerche e applica la relativa politica di sicurezza. Gli hash, i livelli di classificazione e altri meta dati sono conservati in un database diversi, così che le ricerche possano essere effettuate in velocità.
Più punti d’uscita
Sebbene le email rimangano il mezzo principale per condividere informazioni di lavoro, ci sono però rischi aggiuntivi per i file che vengono inviati sul web o via FTP. Questo rende fondamentale il monitoraggio di tutti i punti di uscita. Come deposito centrale delle informazioni il server IGS lavora insieme a email, web e a software per il file transfer sicuro per recuperare I documenti e monitora i flussi di comunicazioni per assicurare che i dati trasmessi siano in linea con le relative autorizzazioni.
Un aiuto per la conformità regolamentare
Nel caso di una violazione dei dati, la funzionalità track and trace del server IGS permette ai responsabili della conformità o ai DPO di vedere chi ha inviato e chi ha ricevuto l’informazione, quando e come. Un sistema di audit e reporting all’interno di IGS permette di creare report sulla provenienza delle informazioni: i responsabili della conformità o i DPO possono vedere i documenti registrati e l’autore della registrazione, per monitorare in tempo reale le violazioni di dati e le infrazioni alla conformità.
Il tracking può rivelare potenziali collusioni tra dipendenti ma può anche aiutare a indentificare una mancanza di comprensione da parte degli utenti delle regole sulla classificazione dei dati e sulla loro condivisione. Così si potrà fare luce sul bisogno di ulteriori informazioni.